 a basic alphabetic indexof SACRIFICING in context
a basic alphabetic indexof SACRIFICING in context
| This will of course only be possible if the researcher knows something about the
appearance of the specific volume sought. Alternatively, some sort of rational order could be used. A rational order is a subject classification. In the Middle Ages a system of nine classes or topics was developed. The topics ranged in descending order from God to the Abyss1. Viewed from the perspective of this rational order, an alphabetical classification might be seen as heretical since Angels will be placed beside the Abyss, and God near the Godless! A modern version of a rationally ordered text (without overt theological overtones) is found in Roget's Thesaurus. This groups together words and phrases with the same or similar meanings, and arranges groups of words in numbered paragraphs. The system is readily manageable, as long as one understands the rational principles upon which the order is based. These are somewhat variable; what is rational or natural to an author may seem bizarre or arbitrary to their readers. Also, the system relies upon alphabetical ordering, without which it would be impossible easily to find a starting point when seeking a word. |
| Some early examples |
| A fascinating example of a system combining rational and alphabetical indexing is
to be found in Gilbert of Poitier's Commentary on the Psalms (circa 1150). This includes signs in the margins of the text which indicate links between the adjacent passage and discussions of the same subject elsewhere in the book. The signs provide an alternative, non-linear, path through the pages of the book. The work has been called the first hypertext system2. In the twelfth century the writers of thematic sermons, in the organization of their writings (in the form of books), contributed to the impetus towards the development of both Order and Access. Other interesting combinations of rational and alphabetical indexing were made in the thirteenth century, when several people were experimenting with procedures for facilitating access to sections of books. Such efforts were influenced and informed by the new styles of preaching, and by the developing universities3. In the early thirteenth century Peter of Capua made a written collection of the 'distinctions' between the different meanings of various key 1Rouse and Rouse (1982: 219). 2Rouse and Rouse (1982: 204-5). 3Rouse and Rouse (1982). |
| 25 |
| terms in the Bible. He sorted entries alphabetically by first letter, and then 'rationally'
within all words beginning with the same letter. So, among the A's, Alitisimus came before Aer, and so on until Abissus, the last of the 81 entries for the letter A1. These developments, however, did not reach fruition until the advent of printing. Alongside the development of alphabetical ordering, the development of accessibility has led to the alphabetical index and the concordance; with the production of concordances and dictionaries: 'we have come to the type of book that can only be searched, for it cannot be read' (Rouse and Rouse)2. |
| Different ways of searching: the concordance and the index |
| Concordances and indices developed continuously from the middle of the twelfth century, although the index only became widespread with the development of printing. A concordance, now commonly known as a key word in context ('KWIC') index, is an alphabetical list of all the words in a text, and the context within which each word occurs. The context given is usually a sentence, but it may be only a few surrounding words, or it can be as much as a paragraph or more. The presentation of a word within its context enables a more accurate assessment of the particular sense in which that word was used. This clarifies the relevance of a particular passage for the researcher, which in turn helps reduce the number of 'false calls'. False calls are references to words with senses other than that with which the reader is concerned . So, for example, there may be two index entries for 'apples', one in a theological discussion, the other horticultural. A KWIC index helps prevent the researcher turning to the wrong page. Concordances have, because of their lengthiness, been relatively rare, generally concerning only a few key texts, such as the Bible and the works of Shakespeare. Now, computers can quickly and easily generate a concordance for any text. This has been seen as providing an automated solution to the amount of human labour involved in constructing indices and tables of contents. However, KWIC indices are not without limitations. When a word appears frequently then the list of occurrences can be daunting to the reader, who may miss the 1Rouse and Rouse (1982: 220). 2(1982: 222). |
| 26 |
| occurrence of greatest relevance. There is no perfect solution to this problem. In
a large document, or collection of documents, some confusion is inevitable. Tables of contents and indices are nothing more than navigation aids and cannot in themselves ensure the discovery of the item sought, nor can they protect against exposure to irrelevancies. One interesting solution would be a subject classification: a large set of occurrences of a single word would itself be classified by subject (shades of a medieval mixture of rational and alphabetical indices). This requires human intervention thus limiting the use of computers in a task that seemed, on the face of it, to be ideally suited to them; so that efficiency decreases as the size of the document or collection of documents increases. As we have already noted, computer-generated links do not work very efficiently. It seems that there is at present no alternative to the conventional method of recording the contents of a document or a collection of documents. We must continue to rely upon the person who produces the guide to the collection we are examining, or else we would have to read through the entire collection. Despite the above, there are advantages to be gained from electronic versions of texts or archives. We have already seen, in the case of the OED, that the electronic version of a text is searchable in ways not practicable in the printed version. Electronic collections, despite the reservations expressed above, have a further benefit: in electronic form it is easy to distribute copies of an original text together with annotations (for instance, the critical edition or reader's guide which I have just argued are indispensable). So the evidence upon which a judgement has been made can be distributed far more easily (more economically) in an electronic medium than on paper. In this sense arguments are made more accountable, the power of the editor to suppress variants by simply omitting them is reduced. The means of criticism can be made readily available to those who are motivated to be critical. |
| Computers as indexing tools |
| Although Hypertext may not enable the revolution claimed for it (see below), computers
have nonetheless revolutionized our access to texts, facilitating both easy navigation within a text (see immediately below) and the discovery of published materials, by way of the citation index (which is discussed in the next chapter). As for navigation within a text, the concordance or KWIC index has already been referred to. is speedily generated. There are free (or shareware) programmes now available which can rapidly |
| 27 |
| generate a KWIC index from a plain file, and versions exist for every flavour of
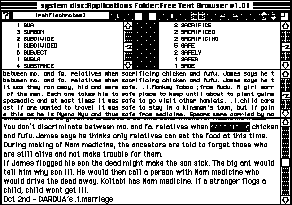
computer (IBM PC compatible, Macintosh, UNIX and some mainframes, inter alia). Some of these programmes also include a hypertextual navigational system, promoting easy access to the text. To conclude this chapter, it is interesting to consider how computers can facilitate access to a text. The following illustration is a view of a computer screen, showing how a key word in context index is used. The programme shows three different windows. Firstly, there is a section of the text under examination (at the bottom of the screen). Secondly, there is a list of all the words which appear the text, and the number of occurrences of each. (On this screen, at the top, two extracts from the word-list are shown). The third window, which is part of the KWIC index, appears in the centre of the screen. Both the word-list and the KWIC index were generated automatically by the computer programme from the text. In this example, I have selected the word 'sacrificing' from the word-list at the top, which tells me that the word appears twice in the text. Below this the programme shows me an extract from the KWIC index, revealing both occurrences of the selected word, with supporting context. Also, I am shown the first appearance of the word 'sacrificing' (highlighted) within the text proper. I can now, using the KWIC index, make a preliminary decision as to which occurrences within the text of the word sacrificing (if any) are relevant to my current interest, and call up any (or none) of those occurrences in the text itself. |
| 28 |
| A KWIC generating application: Mark Zimmermann's Free Text in action |
| Alphabetic list of words - | KWIC index - The 2 instances |
| a basic alphabetic indexof SACRIFICING in context |
| The occurence of SACRIFICING in the main body of the text Other programmes such as TACT as well as constructing KWIC indices allow the text to be analysed and searched in variety of different ways for example looking for collocations - words occurring near one another. This may be helpful in finding or eliminating metaphorical uses of a word (consider searching for 'apple' occurring near the word 'woman' as opposed to 'apple' near the word 'pruning') |
| The use of indices |
| In his review of David Schneider's book 'A critique of the study of kinship' Anthony
Good notes the inclusion of several blank pages and concludes by commenting: 'If the publishers had used a little of this redundant space to include an index, the scholarly value of the book would have been much enhanced1. In the ensuing correspondence Schneider expressed his gratitude to his publisher for 'yielding to my conviction that indexes are a cheap shortcut for the lazy scholar2. Good replied with the comment that 'indexes may or may not be ìa shortcut for the lazy scholarî (though what of the poor undergraduate, or the reader who wishes later on to 1Good (1985:584). 2(1986:541). |
| 29 |
| locate a particular passage); more often, their absence is a shortcut for the lazy
author.' (1986:542). A more neutral summary of the utility of indices may be found in a standard textbook for indexers: |
| The purposes of an index, as stated by McColvin are:- 1) to facilitate reference to the specific item; 2) to compensate as far as possible for the fact that a book can be written in one sequence, according to one plan; 3) to disclose relationships; and 4) to disclose omissions 1. |
| To these purposes Borko and Bernier2 have added:- |
| 5) to answer questions of discovery and foster serendipity; 6) to provide a comprehensive overview of a subject field; and 7) to give nomenclature guidance. |
| Keyword searching |
| Keyword searching is another means by which computers promote access to texts. It
is available in every word processor, and the usual command is 'Find "X"' where 'X' is a word or phrase of your choosing. Generally, the programme offers the facility whether or not to search only for the whole word. (For example, a 'whole word' search for 'sacrifice' will call up only that word but ignore 'sacrifices'. A search which is not restricted to that whole word would also find 'sacrificed' and 'sacrifices'). There will usually be a further choice as to whether the search is to be case-sensitive or not. (A case-sensitive search would find 'sacrifice' but not 'Sacrifice'). There is also the possibility of using 'wild cards' which can stand for any letter, like the blank tile in Scrabble, or any series of letters. This is useful when one wants to find the stem of a word without regard to grammatical inflections. In the screen view illustrated above, a search for 'sacrific*' (where * is the wild card) would have revealed each instance of 1McColvin (1953: 33-4). 2(1978:4). |
| 30 |
| sacrifice,sacrificed and sacrificing. In this simple case, of course, the same task
could be achieved by making a search for sacrific (provided that it was not a whole word search). The unique (if relatively restricted) value of the wild card is that it can be used to find words with the same beginning and ending, regardless of the sequence in the middle. For example, it will search for rhymes or for complete words that begin with sacrific. A wild card is needed to include all the possible endings to the string of letters sacrific while excluding other words which contain that string. In otherwords by searching for whole words which satisfy the description sacrific* we can exclude other words such as desacrifice (if such an ugly term exists). Further possibilities are opened up where different searches may be combined (e.g. find sacr* OR ritual killing). So even a simple word processor provides several ways of searching a text which would be much harder to achieve by other means. With the increasing availability of such tools, it may well be that the way the way in which a reader approaches a text is changing. A further development of the use of wild cards is the so-called soundex searching available in some powerful programmes. Here the programme will automatically look for words which sound like the word specified by the reader, so that a search for the word sought will include sort. This is particularly useful when dealing with a historical archive in which spellings are not standardized. Or in transatlantic modes, where a search for standardized will also reveal standardised. All the searching methods described above duplicate, the function of an index, with the important difference that in an electronic text, each reader can choose their own indexing terms. Advantages over conventional indices are more clearly seen when different search terms can be combined with the logical operators and, or and not. This allows a search to be defined much more precisely. To continue with the illustration above, one may search for occasions where one particular person, such as Geldua, is shown to have performed the sacrifice. Or one could search for sacrific* and (Geldua or Selbon) to find instances in the text when either of those people are mentioned in conjunction with sacrifice. Finally, a note of caution about this sort of free searching throughout a text. As stated above, it puts the researcher in the position of indexer. However, the compiler of any index may use |
| 31 |
| words which describe, but do not actually occur in, the text, so that a cross-reference
from that word alone will not reach relevant parts of the text. Also, several different terms may be united under a single indexing head. At different times this may either help or hinder the reader. The indexer at least has the advantage of reading the work before making the index. Using text searching to examine a large text without reading it may seem like a strange thing to do but, in fact, it is less strange than it may seem, as shown in the example below and in the discussion next chapter. Originally it was hoped that such search facilities would eliminate the need for active human intervention in entering indexing terms, so avoiding also the attendant problems of indexers' inconsistency and arbitrariness. However, as Blair and Maron1 demonstrate, real material contains a rich variety of expressions that cannot be predicted infallibly. They examined the use of a free text searching system on a medium size database, and considered the success rate of computer searches repeated a number of times by people well acquainted with the material in the database. Even in these favourable circumstances, they found that only one in five searches successfully located the specified material. That is to say, the computer searches achieved only a 20% retrieval rate. This illustrates some inherent problems with the use of free text searching (alone) for relevant material. Blair and Maron discussed a complex American legal action, where numerous documents were entered into a computer system so that the defence lawyers could keep track of them. The defence staff were asked to conduct free text searches which were representative of the sort of tasks actually undertaken in the course of working on the case. These searches pointed to documents, and the staff were then asked to assess the relevance of those documents to the question posed.. They then did a variety of other searches, including random sampling of parts of the database to generate other document collections that were also given to the staff. This allowed them to calculate measures for recall and precision2. Recall, the percentage of the relevant documents retrieved, was 20%. In other words, the random selection turned up many 1(1985). 2Recall was defined as the number of relevant and retrieved documents out of the total number of relevant documents. Precision was defined as the number of relevant and retrieved documents out of the total number of documents retrieved. (Blair and Marron 1985: 290). |
| 32 |
| more relevant documents than the search based on that request. Precision, measuring
how many of those retrieved were relevant, was much better, at 79%. Blair and Marons study clearly demonstrates the dangers of keyword searching. A machine can tell you that it has found 5, or even 176 instances of a word or an expression within documentation. However, this gives an impression of comprehensivity which may be misleading. No machine can tell you about the relevant information which has been overlooked. Nor can it direct you to all other relevant books, nor advise which of these can be found in a local library. That is why academic conferences are valued not only for the formal presentations, but also for the informal and invaluable conversations over coffee and beer in between. Advice and references from colleagues constitute a resource which it is unwise to overlook, even if you use the most sophisticated computer searching. Any researcher will probably have some sort of reading list, even if only from a local library catalogue. If the author of one of those works is derided by a respected colleague, then the researcher may delete that work from the list. Conversely, if the respected colleague recommends an alternative author, their name may replace that of the discredited source. This leads to the next chapter: choosing what to read. |
| 33 |